
History of the PDF
PDF (“portable document format”) is a file format originally developed by Adobe, Inc. in the early 1990s to provide consistent electronic display and printing of files across any computer system or application. It was designed to solve the specific problem that documents could be rendered differently depending on the application or the printer showing the file. (For a more modern analog, consider how some websites may display differently depending on the choice of web browser.)
The need for consistent display drives the internal structure of a PDF: a PDF is essentially a list of printing instructions (“draw this glyph at this point on this page”).
PDF Structure
PDFs may include text elements (plaintext words or letters, together with font rendering information), images, vector graphics, fillable forms, and even video and audio content. These printing instructions can appear in any order in the file (not necessarily in the order that the words appear on the screen), and in the case of text elements, may not even correspond to complete words.
For example, the word “2022” may be represented as a single text element, or it might be split into multiple text elements (“20”, “2”, and “2”, say), and there is no guarantee that the place those text elements appear inside the PDF data structure corresponds to the way they are displayed on the screen (they could be printed “2”, then “20”, then “2”, for example).
PDF Encoding
An added complication in the case of text elements is that they may be encoded. The text element for a word is actually represented as a list of numbers. For example, the word “hello” is represented in ASCII encoding as (104 = h, 101 = e, 108 = l, 108 = l, 111 = o). There are other common encoding formats (such as UTF). An encoding format determines which glyphs (or symbols) correspond to each number. Instead of using a standard encoding, a PDF may contain a custom encoding---a custom mapping of glyphs to numbers---which makes it difficult to extract text directly from the PDF. Custom encodings are not necessarily nefarious: sometimes they are used to help compress the document (if only a subset of all possible glyphs are needed, for example).
The easiest way to tell whether a page contains encoded text is to attempt to copy text from the PDF into a text editor (Word, Notepad, etc).
When the document uses a custom encoding, this will produce gibberish text in your text editor. There is no way to tell visually whether a PDF uses a custom encoding! Unfortunately, the user often cannot directly control whether a PDF uses a custom encoding, either: this is typically controlled by the software package that created the PDF. For K-1 packets, it is sometimes the case that certain pages will use a custom encoding, while others will not.
Text elements can be contrasted with scanned document PDFs. When a document is scanned and converted to PDF, each page in the document is packaged as an image (typically, a bitmap format). No text content can be extracted directly from an image: instead, the image must first be run through optical character recognition (OCR). The OCR process used by Reader modifies the input PDF by overlaying text elements on top of each identified character in the input image. This allows Reader to get textual and positional information (which characters were located where); however, font information is lost. Additionally, because characters are sometimes misidentified by OCR (lowercase “L” can be mistaken for the number “1” or for an uppercase “i”, for example), OCR can introduce data errors. For this reason, Reader prefers to work with text elements when present, instead of running every page through OCR or an image processing pipeline.
Best Results with K-1 Reader
A number of factors can impact extraction accuracy with Reader. Here are some tips for achieving good results:
- Uploaded PDFs should be the original document in its original format, with no additions, overlays, modifications, or redactions.
Unsupported PDF Features
- Password-protected files
- XFA forms
Attributes that can negatively impact PDF extraction quality
PDF is a flexible file format that allows K-1s to be constructed in a variety of different ways. Unfortunately, because of this flexibility, some choices made during the creation of the K-1 PDF can impact the ability of Reader to correctly identify and extract information from the document.
Watermarks
“Watermarks” are images or text overlaid on top of a page. Commonly, certain tax preparers will place a watermark with an email address or text like “DRAFT” or “CONFIDENTIAL” on top of the page. Depending on the positioning and nature of the text, these watermarks can result in incorrect data being extracted from the field or fields obscured by the watermark.
The example below shows a type of watermark that can introduce significant extraction errors due to its size and placement.

Scanned documents
Scanned documents represent pages in the K-1 as images, rather than as text. In order to extract information from these types of documents, the scanned pages must be run through optical character recognition (OCR) first. There are several factors that can influence the quality of the OCR process:
- The resolution of the scan. Low-resolution scanned text is harder for OCR to handle, and can introduce character-identification errors.
- Page rotations. Scanned pages are sometimes tilted when scanned, and this can result in character recognition errors, as well as downstream errors in extraction if Reader is not able to correct the rotation.
- Scanning artifacts. Page distortions such as folded or crumpled pages, washed-out text, or similar alterations introduced during scanning can impact the quality of the extraction.
The image below displays a low-resolution scanned document with a slight page rotation. Results for this page would be expected to be worse than for an unrotated, high-resolution scan.
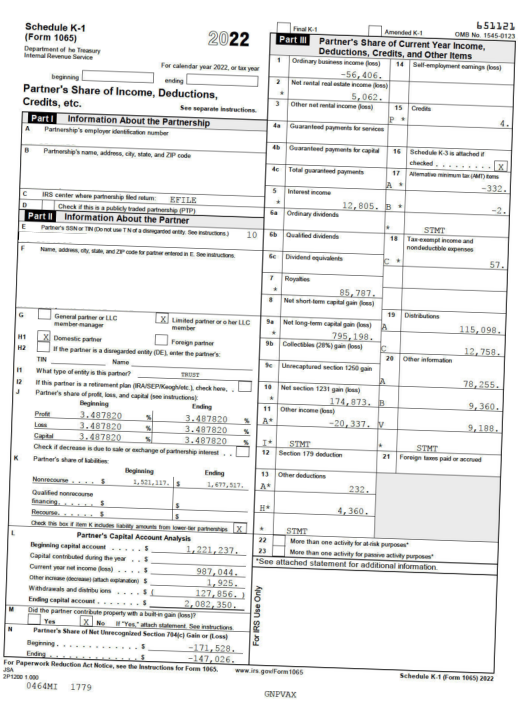
Supported Whitepaper Statement Formats
Reader supports a variety of different whitepaper statements table formats. The format of the table is typically determined by the tax preparation software used to create the K-1, so the examples in this section are organized by tax preparation tool.
The list of examples displayed here is not exhaustive: table extraction may occur correctly for tables that utilize other formats. On the other hand, the grouping of examples by tax preparation software should not be taken to imply that support for these software is complete: tools like CCH and GoSystem provide the user with a significant amount of freedom when constructing whitepaper statements, and a sufficiently determined user may be able to construct tables that cannot be readily parsed by Reader.
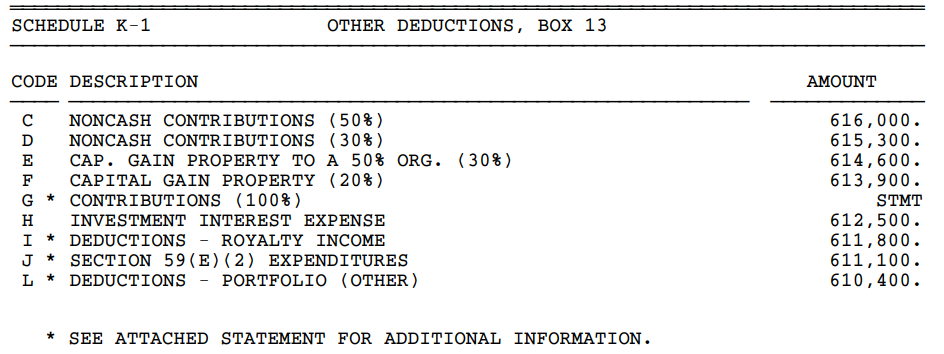
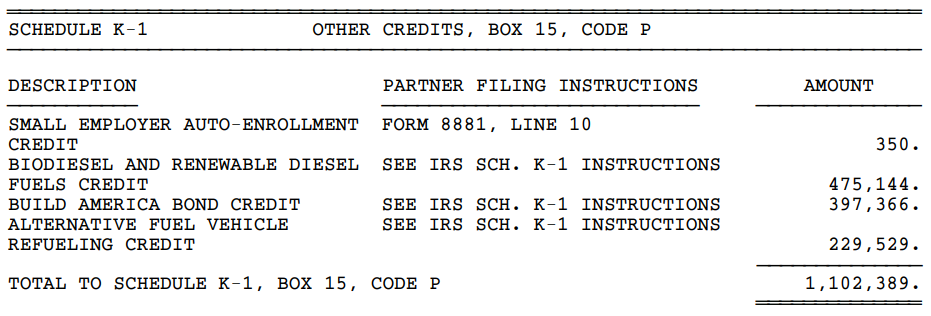
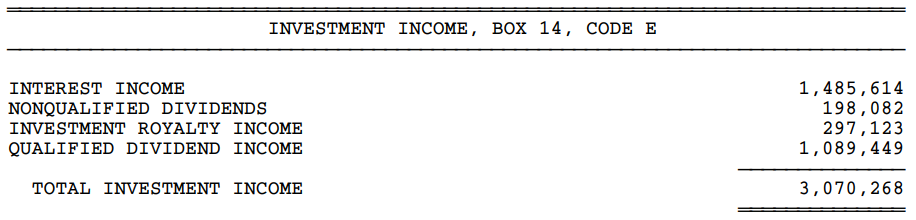
CCH-produced tables with two or three columns:
Two-column GoSystem-produced listings, with or without subsections:


K1 Navigator table formats:


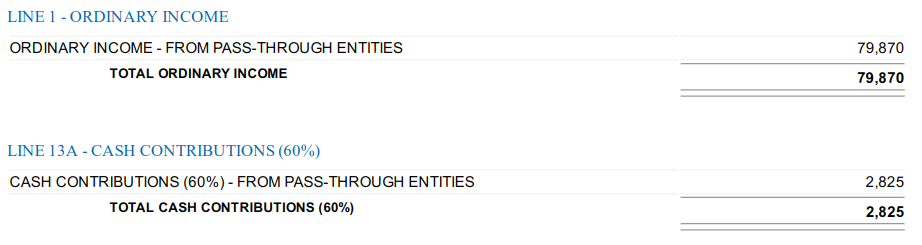
Other common whitepaper statements formats:


Errors, Warnings, and Their Meanings
This section outlines all possible error and warning messages produced by Reader during the extraction process. Note that these errors and warnings are internal only and won't be shown in K-1 Analyzer. Reader consists of multiple sub-components, and each one of these components may generate warnings or errors during the extraction process. When a file extracts incorrectly, these messages can help identify issues in the input file that lead to that result.
Errors vs Warnings
An error occurs when one of the components of Reader breaks during extraction. A warning is a message produced by Reader describing a potential issue uncovered during extraction. Errors indicate that extraction failed; warnings indicate that something was encountered during extraction that may have impacted extraction accuracy. In particular, warnings do not necessarily indicate extraction failures, but, when extraction fails, they can help identify issues that caused the failure.
Every error and warning has an associated numeric code to assist in debugging.
All possible errors
Note that depending on the error encountered, partial extraction may still be returned. For example, if a crash occurs in the Form Extract component for a particular page, extraction for other pages in the document may still be returned.
-
"An unknown error has occurred."
-
code = -1
- This error occurs if the file fails for a reason unrelated to any of the other errors we have in place. These errors require research by K1x to determine what caused the file to fail.
-
-
"The file is too large to be processed. Files should be smaller than 15mb in order to be processed successfully."
-
code = 101
- This error occurs when a file is uploaded that exceeds our file size limit of 15mb. Typically these files are scanned PDFs. If a file is too large, unnecessary pages can be removed from the PDF to reduce file size or the K-1 will need to be entered manually.
-
-
"An unknown error occurred while reading the PDF. Please review the contents of the PDF."
-
code = 200
- This error occurs if the file fails for a reason unrelated to any of the other errors we have in place. These errors require research by K1x to determine what caused the file to fail.
-
-
"Unable to parse the PDF. Please review the contents of the PDF."
-
code = 201
- This error occurs if none of the contents of the PDF match to our bookmark models with a high enough confidence for us to extract anything, or the file is an empty PDF, or the file is not a PDF file. This could be because no K-1 data is present in the file or the format of the K-1 data is very unique and we do not recognize it.
-
-
"The PDF is encrypted and cannot be read. Please enter this K-1 manually."
-
code = 202
- This error occurs if the PDF is password protected, preventing K-1 Reader from opening it. Either a non-password protected PDF must be uploaded or the K-1 will need to be manually entered.
-
-
"The PDF does not contain any pages with K-1 data. Please review the contents of the PDF."
-
code = 203
- This error occurs when we are able to open and read the PDF, but are unable to find any K-1 data to extract.
-
-
"An error occurred when attempting to identify pages with K-1 data. Please review the contents of the PDF."
-
code = 300
- This error occurs when we are able to open and read the PDF, but are unable to find any K-1 data to extract.
-
-
"An error occurred when attempting to extraction K-1 data from the PDF. Please upload this K-1 again."
-
code = 400
- This error occurs when we have an internal error that happens during extraction. If this happens, reuploading the K-1 should resolve the issue.
-
-
"An error occurred during metric calculation. Please upload this K-1 again."
-
code = 501
- This error occurs when we have an internal error that happens during extraction. If this happens, reuploading the K-1 should resolve the issue.
-
All possible warnings
Warnings are returned when issues potentially impacting extraction accuracy are detected. This can range from needing to run OCR (for a scanned document) to encountering a non-numeric value for a numeric field (such as “NONE” instead of 0).
-
"The PDF uses a custom encoding, which may decrease the extraction accuracy. Please review the extracted K-1 data for anything that was missed."
-
code = 251
- Some PDFs use custom encoding for their text, which looks normal to humans, but is interpreted differently when extracting the text. This can usually be seen if copying and pasting the text from a PDF into Notepad. When this is identified, K-1 Reader will attempt to extract the text as if it was a scanned PDF, which may reduce the accuracy of extracted data.
-
-
"OCR was run on this PDF, which may decrease the extraction accuracy. Please review the extracted K-1 data for anything that was missed."
-
code = 252
- Whenever a PDF is scanned or ran through OCR, it impacts extraction accuracy and should be reviewed in more detail.
-
-
"The PDF was decoded and the words are not recognized as English. Please review the extracted K-1 data for anything that was missed."
-
code = 253
- Similar to custom encoding, some PDFs may contain words not able to be identified programmatically as English. In these cases, K-1 Reader still attempts to extract what it can, but accuracy of the extracted data may be impacted and the K-1 should be reviewed.
-
-
"Pages in the PDF were rotated, which may decrease the extraction accuracy. Please review the extracted K-1 data for anything that was missed."
-
code = 254
- Some PDFs may have rotated pages that need to be properly rotated by K-1 Reader in order to extract the data. This is most commonly seen with K-3 pages that are oriented as portrait instead of the native landscape format for the pages. The process of rotating these pages during extraction may impact accuracy and the extracted K-1 data should be reviewed.
-
-
"OCR was run on this PDF and failed, which may prevent entire pages from not being extracted properly. Please review the extracted K-1 data for anything that was missed."
-
code = 255
- A failure to perform OCR on a page does not fail the entire file for reading, only the page it failed on. When this happens, part of the PDF may be extracted normally, but certain pages are missed entirely. The extracted K-1 data should be reviewed to identify what was missed and enter it manually.
-
-
"K-1 data was not found in the contents of this PDF. Please review the contents of the PDF."
-
code = 351
-
Compared to the error where no K-1 data was found, this warning means that there was some data extracted from the PDF, however we didn't find K-1 data specifically. The PDF should be checked to make sure a K-1 is present and data may need to be entered in manually.
-
-
"K-1 data was identified, but was unable to be extracted from the PDF. Please review the extracted K-1 data for anything that was missed."
-
code = 451
-
The bookmarking model identified that a K-1 is present in the PDF, but for a number of reasons it was not able to be extracted. The PDF should be checked to make sure a K-1 is present and data may need to be entered in manually.
-
-
"A non-numeric value was encountered for a numeric field, which will cause the value to be empty. Please review the extracted K-1 data for anything that was missed."
-
code = 461
- In some cases, text such as "VARIOUS" or "NONE" may be used in a field on the K-1 where a numeric or percentage value is expected. In these cases, K-1 Reader will extract the data, but empty it out as strings are not a valid value for those fields.
-
-
"An invalid code value was encountered, which will cause the value to be empty. Please review the extracted K-1 data for anything that was missed."
-
code = 462
- In some cases, a code may be used or is identified in a field on the K-1 where it shouldn't be. In these cases, K-1 Reader will extract the data, but empty it out as the code is not a valid value for those fields.
-
-
"An invalid item detail value was encountered, which will cause the value to be empty. Please review the extracted K-1 data for anything that was missed."
-
code = 463
- In some cases, an item detail for a line may be invalid. In these cases, K-1 Reader will extract the data, but empty it out as the detail value is not a valid value for those fields.
-
-
"Some form fields could not be reconciled. Please review the extracted K-1 data for anything that was missed."
-
code = 464
- When extracting line details or other sub-lines that total up to a line value, K-1 Reader will perform a check to make sure the sum of the details adds up to the expected total. If they don't, we return this warning so the details can be checked for what was missed.
-
-
"No K-1 data was extracted from this PDF. Please review the contents of the PDF."
-
code = 551
- When no errors occur from K-1 Reader, but nothing was extracted from the PDF, this warning will be returned. The K-1 should be reviewed to make sure it contains K-1 data.
-
-
"Metrics could not be logged for this file."
-
code = 552
-
This warning is internally only and does not necessarily mean there is anything to review with the K-1.
-
- "A whitepaper statements table does not match the extracted form values."
- This warning will be returned with a specific table name from the whitepaper statements it is in reference to. This warning means that we extracted both the facepage value and the statement details for a line, but the sum of the details didn't match the facepage amount. When this happens we ignore the detail lines and use the facepage value, prioritizing the correct amount over the details. If details are needed in K-1 Analyzer, they must be manually entered.
FAQs
- What is the file size limit on a K-1 file for upload?
- Files larger than approximately 15mb will fail to upload. Typically these are scanned documents with a large number of pages.
- How many K-1s can I upload at one time?
- Assuming all files are within the file size limit, there is no limit to how many you can upload at one time.